
DeepGEMM(Deep General Matrix Multiplication)是DeepSeek公司最新开源的通用矩阵乘法运算库,其主要目的是提高GPU的浮点运算效率。众所周知,深度学习中最重要的运算之一就是矩阵乘法,不管是前向传播还是反向传播都涉及。GPU对于数据运算的精度主要包括FP64、FP32、FP1、FP8等,FP8是一种8位浮点数格式,有NVIDIA Hopper架构引入,主要优势在于占用的内存和计算资源更少,同时保持足够的精度。DeepGEMM就是专为这一架构设计的。
DeepGEMM开源地址为:https://github.com/deepseek-ai/DeepGEMM 。从硬件需要上可以看出,这一运算库只适用于工业级计算显卡如H100、H200、H800等Hopper架构下的显卡,而像我们常用的A系列、30系列显卡主要使用Ampere架构、40系列显卡主要采用Ada架构。因此,复现成本较高、对于普通科研人员来说无法直接使用。不过,我们可以简单看一下算法的源码,了解一下优化思路,为后续的硬件加速奠定基础。
据项目代码介绍,作者利用了 CUTLASS 和 CuTe 中的一些概念,但它避免了对它们的模板或代数的严重依赖。相反,该库的设计是为了简单,只有一个核心内核函数包含大约 ~300 行代码。CUTLASS和CuTe我们后面再说,先来看看~300行代码的情况。
核心代码应该在“include/deep_gemm”文件夹下,均采用CUDA C++编程实现。包括:fp8_gemm.cuh、mma_utils.cuh、scheduler.cuh、tma_utils.cuh、utils.cuh。其中fp8_gemm.cuh包含了运算库的主要实现,在代码的开头引用了CUTLASS和CuTe的相关头文件,以及自定义的其他四个头文件。代码运行可分为六个阶段,采用生产者-消费者模型实现计算与内存操作的深度流水:
初始化阶段:
TMA线程组(128线程)预取所有Tensor Map描述符
初始化分布式屏障系统(每个流水阶段配full/empty双屏障)
计算线程组预加载B矩阵的缩放因子到共享内存
数据预取流水:
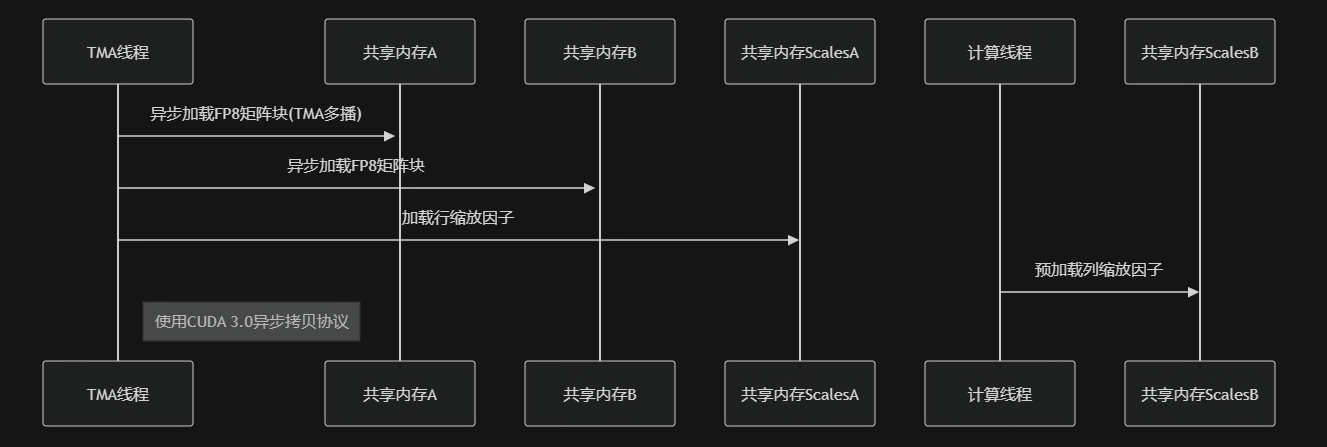
计算核心流水:
Warpgroup级WGMMA指令展开(每个线程组处理BLOCK_M×BLOCK_K×BLOCK_N子矩阵)
动态标量融合:实时计算A×B缩放因子乘积
累加器分阶段归约(支持非对齐K维度)
屏障同步系统:
双相位屏障设计(奇偶计数器)
TMA线程通过full屏障通知数据就绪
计算线程通过empty屏障释放缓冲区
结果写回阶段:
使用STSM(Shared to Shared Move)优化数据布局
TMA存储引擎异步写回全局内存
4D Swizzle模式消除存储体冲突
动态负载均衡:
Scheduler组件实现三种调度策略:
Normal:标准矩阵划分
Grouped:分组GEMM批处理
GroupedMasked:带掩码的分组处理
虽然DeepGEMM只能用于Hopper架构,但我们了解到了CUTLASS——NVIDIA自家的GPU加速运算库。虽然现在DeepGEMM的运算效率更快,但CUTLASS运算库的好处在于适配Volta、Turing、Ampere、Ada、Hopper 和 Blackwell 架构,几乎可以覆盖所有人使用的显卡版本,更有利于普通个人用户拿来加速自己的GPU程序。